Snowflake Access and Roles#
Data access and data governance are deep topics that we won't attempt to cover fully here, but we will try to lay out our general philosophy of setting up an analytical warehouse access model, how our default role structure works, and how it could be extended.
There is no one-size-fits-all solution when it comes to database security, so we try instead to offer a robust out-of-the-box security model that can be extended and built upon when the need arises.
Access control levels#
There are many levels of data governance within a database, but the primary ones break down into these types:
- Domain- or table-level access
- Who can see attendance data?
- Who can see HR data?
- Row-level access
- Which students should a user see within the attendance table?
- Column-level access
- Do any columns need to be hidden from certain users, such as addresses or phone numbers?
- Development environments
- Who needs to see in-development versions of data models, before they're released to production?
Philosophy#
Who needs a database account?#
Databases are a very technical interface, and most consumers of education data will not be connecting directly to the database and running queries. The majority of data interactions will be mediated by another layer, such as a BI tool or reporting framework. These tools are the proper home for much of the granular data governance questions: who can see which reports, and which students are visible within those reports.
Our target audience for database roles then is not every possible user of data, but rather the technical folks who will be managing these systems, or asking the types of questions for which reports have not yet been built. These are generally district staff: data analysts, BI developers, researchers, etc.
For these staff our task is often quite simple: district data analysts can see across all domains, all rows, and all columns. Indeed, they often already have this access in the source systems that populate Ed-Fi. The only distinction left is whether their jobs require access to development environments, or the ability to develop dbt models themselves.
Write access#
Generally our policy is that human accounts never write data to production spaces, and even in non-production spaces they don't do so directly.
EDU is a code-governed framework, which means all tables and transformation logic are written in code, never created by hand. This ensures the whole process is fully auditable, transparent, and documented.
It is possible to create so-called 'scratch schemas' where authorized users can create new tables or views, but we highly recommend learning dbt instead, so these tables can be incorporated into the automated build process.
Role hierarchies#
We use a hierarchical structure for roles as described in Snowflake's best practices documentation.
Roles are divided into two categories:
Access Roles govern read/write access to database objects like tables
and views. They are not granted directly to users, but make it easier to manage
such grants: many teams and people need read access to the analytics database,
so an access role like db_analytics_r collects this permission in one place.
Functional Roles align to teams, such as district_analyst or dbt_developer,
and these are the roles granted to people and services. Warehouse access
is granted to functional roles so that workflows for different teams are kept
separate.
Access roles are then granted to functional roles as appropriate: an analyst
needs read access to analytics, whereas a dbt developer needs read access to
raw data and write access to dev_analytics, the development area.
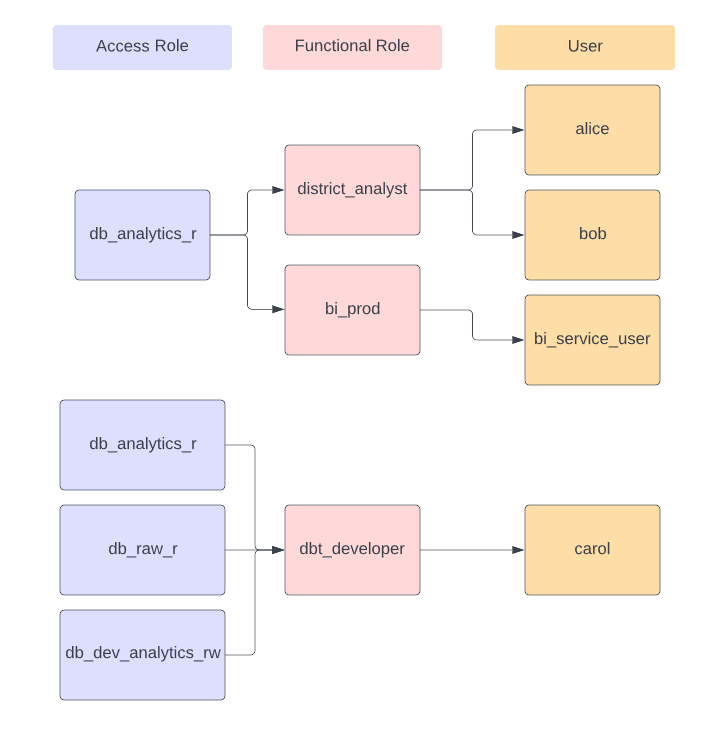
Note that the functional roles district_analyst and bi_prod have the same
access roles, but are separated into different functional roles. This allows
us to separate them into their own compute, so that heavy BI usage won't affect
the analyst's experience and vice versa. It also allows for separate monitoring
of query performance for different teams with different needs.
It's important not to over-complicate functional roles by creating too many functionally equivalent roles, however. Multiple analyst or research teams may have very similar data access needs, and pooling them into the same role simplifies management, and pooling them into the same compute warehouse can save cost.
Best practices#
Keep user-count small#
As noted above, the number of users who would benefit from direct query access is generally much smaller than the number of users who consume data, and direct-query users tend to have the simplest governance requirements. By keeping database access only for those that actually need it, our management task is much simpler.
Integrate Single Sign On#
SSO allows us to leverage existing best practices for password strength and rotation, MFA, and other access governance. It also automatically deactivates accounts of exited staff, so we don't have another surface to manage.
The official documentation covers the SSO process, and there are also step-by-step guides for platforms like ADFS, Azure AD, and Okta, among others.
Hint
When using SSO, each user's login_name must match the name reported by
the SSO service, which is most commonly their full email address.
Use network controls#
Limit access to the warehouse only to known IP ranges belonging to the district, contractors, or cloud tools that need to talk to the warehouse. This adds an extra layer of protection against phishing (though hopefully you're using SSO with MFA as well), because access from the open internet is blocked.
In Snowflake, this is managed through Network Policies.
Hint
Using network policies with cloud-based BI services is a bit more complicated.
Cloud BI services generally publish a list of IP ranges used by their services which are updated weekly. This process can be automated within the EDU framework.
PowerBI users could alternatively leverage the Power BI gateway, which routes connections through your local network.
Separate human accounts from service accounts#
Each human being who connects to the database should have their own account under their own name (no account or credential sharing).
But there are also many service accounts that may need access, such as the processes that load or transform data, or reporting services. Since these are not tied to any particular human, they will not pass through SSO and should instead use strong passwords or key pair authentication.
Only the maintainers of the service should have access to these service accounts so they can set up the integrations, and should not use them directly.
Limit administrative access#
Very few users should have high level administrative access, and as little work as possible should be done from administrative roles.
Centralize or Deputize user creation and grants#
Creating users and granting them roles can be handled either centrally or by each team.
A central approach would designate a small number of high power users to create new users and grant roles to them. These people would be responsible for understanding the functional roles used within the system and how to sort users into these categories.
A deputized approach would create a role like district_analyst_admin. Users
with this role would be empowered to create new users, and grant existing users
the district_analyst role, but would not be able to grant any other roles.
A centralized approach is generally easier if the total number of users and the rate of change in users is low. In cases with high user churn, or where few or no users should have access to all data (such as multitenant environments), a deputized approach is better.
Hint
If you're using SSO, an SSO admin will generally have to authorize users for the Snowflake service before they'll be able to log in.
Multitenancy and Extensions#
Multitenancy#
For multi-tenant environments like states, district collaboratives, or charter networks things become slightly more complex, but work similarly.
Rather than having one district_analyst role, we would have one per tenant,
leveraging row access policies to recreate the same district-level experience as
a single-tenant warehouse.
There is an EDU package to manage this process that's quite simple to integrate, which will be releasing soon. Contact us if you'd like to know more.
Extensions#
Creating new functional roles or teams is simply a matter of deciding what data they should have access to, granting the appropriate access roles, and creating a warehouse for the team (if necessary).
If there must be database users with less than full-district access, row access policies can be created that do user-based lookups against staff-school associations.
For more complex applications, such as column-level security, anonymization for research, or data sharing, contact us!