Assessment Query Guide#
Introduction#
This is a query guide for using the EDU data warehouse to assemble datasets with assessment data for answering analytics questions.
This guide aims to:
- Provide key information on the relevant tables and variables available in EDU
- Outline key pre-processing steps implemented on the relevant tables
- Demonstrate common use cases that should help you get started on:
- Exploring data
- Assembling datasets containing variables that are sourced from different tables
- Accessing data stored in columns in a non-standard format
- Implementing explainable processing steps for deduplicating data
- Composing more complex queries
Important notes
🔧 Implementation variations: This documentation is based on a standard implementation of EDU. Site-specific implementations may have additional data processing steps and features built out that this document does not cover. Please consult the dbt Docs of your specific implementation for more details.
📚 Prerequisites: This document assumes knowledge of SQL and common database concepts such as dimensional modeling.
💡 Learning approach: Examining the common use cases below should help you think critically about the factors to consider when combining assessment data with other types of student data available in EDU.
Which tables contain assessment data?#
EDU contains assessment data both at the overall test score level and also at the sub-score level. For example, sub-scores for a reading assessment could be for vocabulary, writing, etc. These two levels of test data are stored in different tables.
This section will walk you through all tables containing assessment and objective assessment (sub-score level) data. It will also highlight some notable variables in each of these tables.
Note that this section includes links to a general EDU dbt Docs site. It is likely most helpful to consult the dbt Docs generated for your specific implementation.
Assessment tables#
The following tables contain student-level overall test scores and information about the tests:
- fct_student_assessment
- This table contains student-level assessment records.
- Descriptions of some useful columns are provided below:
k_student_assessment- This is a surrogate primary key that uniquely identifies each observation in this table. There is one record per student-assessment event.k_assessment- This is a surrogate key that uniquely identifies each assessment (e.g. MAP, STAAR, etc.) and is a foreign key with reference to the dim_assessment table (described below). This key can be used to join additional assessment information from the dim_assessment table.k_student- This is a surrogate key that uniquely identifies a student for a given school year and is a foreign key with reference to dim_student. This key can be used to join additional student information from the dim_student table.k_student_xyear- This is a surrogate key that uniquely identifies a student across all available school years.administration_date- Date and time for when an assessment is completed by the student.when_assessed_grade_level- The grade level of the student-assessment, as sourced from the assessment data loaded to Ed-Fi. Our governance recommendation is for this to represent the assessed grade when available. But queryers can not assume this is the case, and need to understand the underlying context for each assessment.scale_score- The scale score achieved by the student for the assessment.v_other_results- Additional data about the assessment that is not stored in the other formatted columns on the table. Note the data stored in this column is in the form of a JSON object containing values for multiple variables. One of the use cases described below demonstrate how to extract specific variable values from this JSON object.
- dim_assessment
- This table contains information about different assessments.
- Descriptions of some useful columns are provided:
k_assessment- This is a surrogate primary key that uniquely identifies each observation in this table.assessment_identifier- A unique number or alphanumeric code assigned to an assessment.assessment_title- The name of the assessment (e.g. NWEA MAP, STAR Early Literacy, etc.).assessment_family- Groups related assessments together (e.g., "IB" for International Baccalaureate assessments). Often more useful thanassessment_identifierwhen you want to group multiple assessment identifiers together for analysis.academic_subject- The subject for the assessment (e.g. Science, Reading, Mathematics, etc.).namespace- indicates the source from which the assessment data is pulled. This link contains more information regarding how the values in the namespace column are formulated.
Surrogate keys
For each of the surrogate keys mentioned above, 'k_....', you can determine the natural primary key that the surrogate primary key is composed of from the dbt Docs for each table. This information can be accessed either in the Details or Code section of the dbt Docs page for a given table.
Objective assessment tables#
The following tables contain student-level assessment sub-scores and information about those sub-scores:
- fct_student_objective_assessment
- This table contains student-level assessment sub-score records.
- Descriptions of some useful columns are provided:
k_student_objective_assessment- This is a surrogate primary key that uniquely identifies each observation in this table.k_objective_assessment- This is a surrogate key that uniquely identifies each objective assessment.k_student_assessment- This is a surrogate key that uniquely identifies each student-assessment event. This key associates the objective assessment record with the student-assessment event (e.g. NWEA Map, STAAR, etc.) it is a part of.k_student- This is a surrogate key that uniquely identifies a student for a given school year and is a foreign key with reference to dim_student.scale_score- The scale score achieved by the student in the objective assessment (subscore).
- dim_objective_assessment
- This table contains information about different objective assessments.
- Descriptions of some useful columns:
k_objective_assessment- This is a surrogate primary key that uniquely identifies each observation on this table. This key can be used to join the dim_objective_assessment table with fct_student_objective assessment table to add on more information for each objective assessment.k_assessment- This is a surrogate key that uniquely identifies each assessment and is the foreign key with reference to dim_assessment. This key can be used to merge on more parent assessment level information for each objective assessment.
What processing has already been done?#
This section walks through the pre-processing done on the assessment data before it's made available to the tables mentioned earlier.
What validations and/or drops have been done?#
- If a student is not present in the warehouse in any year, their assessment records are dropped. In these instances, the student does not exist in
dim_student, and does not have ak_student_xyearvalue — a key identifying a student uniquely across multiple years. - Student assessment records where the
academic_subjectvalue is NULL are dropped. Note,academic_subjectis inferred fromassessments(if the assessment is single-subject) or score result.
What validations and/or drops have NOT been done?#
- Invalid scores might still be included.
- Invalid test events might still be included.
- If a student took a test twice and the test vendor considers these separate test events, both of these test record will be included. Depending on the analytics use case, you may need to remove these duplicate records. See how to de-duplicate assessment records below.
Assessment configuration (use of seeds)#
EDU relies on configuration via dbt seeds. For example, with a specific assessment, we need to tell EDU which scores exist, what the thresholds for performance level are, etc. Depending on the assessment and applications, a number of seed tables need to be populated for an assessment to make it to the warehouse and have key fields populated. The table below provides an example of a seed table for configuring MAP Growth scores. In this configuration, the original_score_name (as provided by the assessment vendor) is mapped to a normalized_score_name (standardized across EDU). This mapping creates a common structure for score reporting that can be used consistently in fct_student_assessment and downstream tables.
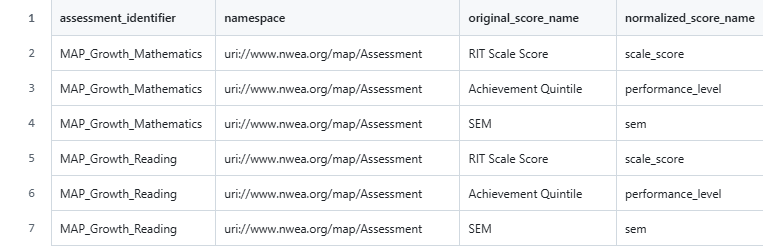
What is namespace / What are these uris?
Namespace URIs are used in Ed-Fi to uniquely identify resources that are source-specific. You can see here that nwea.org is part of the namespace, signaling that the 'MAP_Growth' assess identifier was sent to Ed-Fi by nwea.org (or, a vendor working on behalf of NWEA).
We need these for a couple reasons:
- To enforce that only vendors with access to the nwea.org namespace can overwrite metadata about NWEA assessments (this is necessary in a world where many vendors are sending assessment data to one place).
- To allow for multiple vendors to have overlapping codes for things without causing duplicate errors. e.g. both might have a performance level called 'Low'.
Namespace therefore is included in assessment seeds so that when joining to assessment data, our joins correctly enforce the grain of assessment metadata and don't incorrectly associate information from assessment B to rows about assessment C.
Common use cases#
The queries listed in this section should help you get started with exploring the different types of assessment data available in EDU and assembling datasets for common analytic use cases. The first few use cases will walk you through how to join different tables in EDU containing different elements of assessment data. The later use cases will address how you can apply specific processing rules that may be useful for common analytic use cases.
Placeholder values
Note that in the queries provided in this section, values used for filtering using the WHERE clause may be placeholder values. Make sure to replace these with the actual values of the columns you wish to filter using.
Quick reference#
| Use Case | Description | Complexity |
|---|---|---|
| Basic table joins | Join assessment events with assessment metadata | Beginner |
| Assessment inventory | Count available assessments by type | Beginner |
| Access custom fields | Extract data from JSON columns | Intermediate |
| Deduplicate records | Keep highest score per student/assessment/year | Intermediate |
| Add demographics | Join student demographic information | Intermediate |
| Latest demographics | Use most recent demographic data across years | Advanced |
| Complex business rules | Combine deduplication with latest demographics | Advanced |
How to join assessment event data with assessment characteristics data?#
What you'll learn: How to join assessment event data with assessment metadata to create a comprehensive dataset.
While putting together assessment research datasets, it's convenient to think of fct_student_assessment as the base table to start from. This table contains student assessment records but does not contain much information regarding the assessment. Additional information for assessments can be merged on from dim_assessment. The query below demonstrates how to join these two tables.
Dataset may contain duplicates
Note that the dataset generated by this query may contain duplicates and/or invalid scores. The use case in this section solely aims to demonstrate how to join the two key assessment tables together. Additional processing steps to refine assessment dataset will be demonstrated in use cases that follow.
-- Basic join between assessment events and assessment metadata
SELECT
fct_student_assessment.school_year,
fct_student_assessment.administration_date,
dim_assessment.assessment_identifier,
dim_assessment.assessment_title,
dim_assessment.academic_subject,
fct_student_assessment.when_assessed_grade_level,
fct_student_assessment.scale_score,
fct_student_assessment.performance_level
FROM analytics.prod_wh.fct_student_assessment
JOIN analytics.prod_wh.dim_assessment -- join for assessment information
ON fct_student_assessment.k_assessment = dim_assessment.k_assessment
WHERE fct_student_assessment.school_year IN ('2023', '2024') -- subset to specific years
AND fct_student_assessment.scale_score IS NOT NULL; -- subset to non-missing score values
Which assessments are available?#
The query below demonstrates a way to return record counts of different types of assessments available in the warehouse. Note that a similar query can be run on dim_objective_assessment as well.
SELECT
dim_assessment.tenant_code,
dim_assessment.school_year,
dim_assessment.academic_subject,
dim_assessment.assessment_family,
dim_assessment.assessment_identifier,
dim_assessment.namespace,
count(*) as n_assessment_records
FROM analytics.prod_wh.fct_student_assessment -- using as base table to get assessment event counts
JOIN analytics.prod_wh.dim_assessment -- join for assessment information
ON fct_student_assessment.k_assessment = dim_assessment.k_assessment
GROUP BY
dim_assessment.tenant_code,
dim_assessment.school_year,
dim_assessment.academic_subject,
dim_assessment.assessment_family,
dim_assessment.assessment_identifier,
dim_assessment.namespace
ORDER BY dim_assessment.assessment_identifier desc, dim_assessment.namespace, dim_assessment.school_year;
Group by variables
Note that the group by variables selected in the query above were carefully chosen to provide record counts by assessment taking into account the uniqueness constraint of the dim_assessment table. These variables form the primary key for the table. This ensures that the counts provided are both accurate and intuitive. The columns section of the dbt Docs should contain information about the variables that define the primary key for a table.
School-level metrics
For generating aggregate metrics at the school level, you might need to join an assessment table with fct_student_school_association to determine where a student is enrolled. The resulting table from this join might have duplicate observations at the student-assessment level due to potential one-to-many joins. This is possible because a student can be associated with multiple schools during a given school year. In this scenario, if your use case requires each student to be associated with only one school for a given school year, you will need come up with a specific business rule(s) for identifying one school per student and incorporate this into your query.
How to access non-standard assessment information?#
Some assessments may contain data specific for that assessment. For example, NWEA MAP provides growth projections based on a student's assessment score history. Such non-standard assessment specific information is stored in the v_other_results column in an array format. NWEA MAP provided "Fall-To-Winter Conditional Growth Index" Non-standard and assessment specific data such as this can be stored in the v_other_results column in an array format. The query below demonstrates how access assessment specific fields within the v_other_results column
Some key assessment information, such as what language a specific assessment was administered in, may not be available in the formatted columns of the fct_student_assessment table. This key information may be populated in variables that are stored in an array format within the v_other_results column. These are intentionally kept in v_other_results, because they are assessment-specific. The only columns brought into standard formatted columns in fct_student_assessment are generic scores, as configured by your implementation of xwalk_assessment_scores. For example, certain MAP assessments provide a Fall-To-Fall Growth measure. The query below demonstrates how this information can be pulled out.
SELECT
fct_student_assessment.school_year,
fct_student_assessment.k_student_assessment,
fct_student_assessment.k_student,
dim_student.grade_level,
fct_student_assessment.administration_date,
dim_assessment.assessment_identifier,
dim_assessment.academic_subject,
fct_student_assessment.scale_score,
fct_student_assessment.performance_level,
fct_student_assessment.v_other_results:"Fall-To-Fall Observed Growth"::float as map_growth_index -- demonstrates how to access data stored in array
FROM analytics.prod_wh.fct_student_assessment
JOIN analytics.prod_wh.dim_assessment -- join assessemnt dim table for assesment information
ON fct_student_assessment.k_assessment = dim_assessment.k_assessment
JOIN analytics.prod_wh.dim_student -- contains student infomrmation
ON fct_student_assessment.k_student = dim_student.k_student;
How to deduplicate assessment data?#
For some analytic use cases, you may want to have a single student observation for a given period of time. The query below provides an example of how to deduplicate assessment data. Here, assessment data is deduplicated by keeping the maximum student scale score for a specific assessment in a given school year.
SELECT
fct_student_assessment.k_assessment,
fct_student_assessment.k_student_xyear,
fct_student_assessment.school_year,
dim_assessment.assessment_identifier,
dim_assessment.academic_subject,
fct_student_assessment.scale_score,
fct_student_assessment.performance_level
FROM analytics.prod_wh.fct_student_assessment
JOIN analytics.prod_wh.dim_assessment
ON fct_student_assessment.k_assessment = dim_assessment.k_assessment
WHERE dim_assessment.assessment_identifier = 'YOURASSESS' -- fiter to specific assessment
-- OR filter on family
-- WHERE dim_assessment.assessment_family = 'YOURASSESSFAMILY'
QUALIFY 1 = row_number() -- keeps only observation with highest test score for each student, assessment and school year
OVER (PARTITION BY fct_student_assessment.k_assessment,
fct_student_assessment.k_student_xyear,
fct_student_assessment.school_year
ORDER BY fct_student_assessment.scale_score desc);
Note about k_student_xyear
Note that k_student_xyear is used here because k_student values may be missing in assessment years when a student doesn't have a corresponding dim_student record. This could happen in an implementation of EDU where vendors have loaded historic assessment data to the warehouse in years prior to the earliest roster data from an Ed-Fi ODS (e.g., district A implement Ed-Fi for the first time in 2024, but loaded assessments for 2023 to their warehouse).
How to join student demographics data to assessment data?#
At this point, you know how to join dim_assessment to fct_student_assessment and create a dataset that contains student assessment events and also additional assessment information. This section demonstrates how you can join dim_student onto this assessment dataset to add student demographic data.
Dataset may contain duplicates
As noted earlier for the assessment dataset composed from fct_student_assessment and dim_assessment, the dataset generated by the query here may also contain duplicates and/or invalid scores and, may also contain multiple student assessment records for a given school year. The use case in this section solely aims to demonstrate how to join on dim_student. Additional processing steps to refine each data type will be demonstrated in later use cases.
Student demographic data sources
Note, student demographic data exist in multiple places in the warehouse. This query will show you how to join to dim_student for wide demographic values unique on k_student. This is a great place to start. If you are building an application with a dropdown for demographic category, you may instead want to join to fct_student_subgroup, to get long demographics in a standard shape, unique on k_student and k_subgroup. If you want to dive into the details of program-related info (e.g., student special education program information), you may instead want to join to tables like fct_student_special_education_program_association. But be careful with duplicates in these program tables.
Student demographic data can be joined onto assessment data using the dim_student table. When joining on this table, it is useful to think through which key is most suitable for joining. Here are the two keys that could potentially be used for joins:
k_studentis a surrogate key which is composed of the student's unique id and a given school year. For a specific student, this key changes from school year to school year.k_student_xyearis another surrogate key that is consistent across multiple years. Thus, making this key more suitable for use cases that require a student to be tracked across multiple years.
Note about k_student
Note that k_student in fct_student_assessment is sometimes null because the warehouse might have historical assessment data for years when dim_student records might not be available. This necessitates a processing rule for linking student assessment records to demographics data across years.
SELECT
fct_student_assessment.school_year,
fct_student_assessment.k_student_assessment,
fct_student_assessment.k_student,
dim_student.grade_level,
dim_student.race_ethnicity,
dim_student.gender,
fct_student_assessment.administration_date,
dim_assessment.assessment_identifier,
dim_assessment.academic_subject,
fct_student_assessment.scale_score,
fct_student_assessment.performance_level
FROM analytics.prod_wh.fct_student_assessment
JOIN analytics.prod_wh.dim_assessment -- join assessemnt dim table for assesment information
ON fct_student_assessment.k_assessment = dim_assessment.k_assessment
JOIN analytics.prod_wh.dim_student -- contains student infomrmation
ON fct_student_assessment.k_student = dim_student.k_student
WHERE dim_assessment.assessment_identifier in ('abcassess1', 'abcassess2')
AND fct_student_assessment.school_year in ('2022', '2023')
AND dim_student.grade_level in ('3', '4') -- subset to specifc grade levels
AND fct_student_assessment.scale_score is not null;
How to join demographics data from the most recent school year?#
The query below demonstrates how to join only the most recent year of demographics data available from dim_student to the fct_student_assessment table. This ensures that the final dataset contains consistent student demographics data across multiple years of assessment data.
Common scenario
A common scenario where implementing this specific business may be helpful is when student demographics data may not be available for all years in which assessment data is available. The most recent year of demographics data can be joined across all years of assessment data.
Note about k_student_xyear
Note the use of k_student_xyear here, as we need to track student records across different school years.
-- this CTE finds the most recent student record and uses that record as the source of student demographics
WITH latest_k_student as (
SELECT
k_student_xyear,
k_student
FROM analytics.prod_wh.dim_student
QUALIFY school_year = max(school_year) OVER(PARTITION BY k_student_xyear)
)
SELECT
dim_student.gender,
dim_student.race_ethnicity,
fct_student_assessment.* -- adds on all columns from the assessment table
FROM analytics.prod_wh.fct_student_assessment
JOIN latest_k_student
ON fct_student_assessment.k_student_xyear = latest_k_student.k_student_xyear
JOIN analytics.prod_wh.dim_student
ON latest_k_student.k_student = dim_student.k_student;
Note that by tweaking the condition for how the year is chosen in the query above, you can also choose demographics data from other available school years, e.g. by switching max() with min(), you can choose demographics data from earliest available school year.
How to apply business rules to multiple tables? (Find highest scale score linked to latest demographics)#
The query below demonstrates how ideas presented in the earlier two use cases can be brought together to compose a more complex query. This query creates a dataset where a student has a single assessment record containing their highest scale score for a given school year and assessment and their most recently available demographics data across all years of available data.
WITH latest_k_student as (
SELECT
k_student_xyear,
k_student
FROM analytics.prod_wh.dim_student
QUALIFY school_year = max(school_year) OVER(PARTITION BY k_student_xyear)
)
SELECT
fct_student_assessment.k_assessment,
fct_student_assessment.k_student_xyear,
fct_student_assessment.school_year,
dim_student.gender,
dim_student.race_ethnicity,
dim_assessment.assessment_identifier,
dim_assessment.academic_subject,
fct_student_assessment.scale_score,
fct_student_assessment.performance_level
FROM analytics.prod_wh.fct_student_assessment
JOIN analytics.prod_wh.dim_assessment
ON fct_student_assessment.k_assessment = dim_assessment.k_assessment
JOIN latest_k_student
ON fct_student_assessment.k_student_xyear = latest_k_student.k_student_xyear
JOIN analytics.prod_wh.dim_student
ON latest_k_student.k_student = dim_student.k_student
WHERE dim_assessment.assessment_identifier = 'YOURASSESS'
and fct_student_assessment.school_year = '2023'-- fiter to specific assessment and year
QUALIFY 1 = row_number() -- keeps only observation with highest test score for each student, assessment and school year
OVER (PARTITION BY fct_student_assessment.k_assessment,
fct_student_assessment.k_student_xyear,
fct_student_assessment.school_year
ORDER BY fct_student_assessment.scale_score desc);
Business rules
Note that the query above implements very specific business rules in order to dedupe students' assessment data within a school year and retain a single record of demographics data across multiple school years. The business rules implemented here may not be suitable for your specific use case. The query above aims to only demonstrate how specific business rules can be implemented on data being pulled from different tables.
Haven't found what you're looking for?
Looking for additional use cases? Want similar guides for other domains? Contact us with your thoughts!